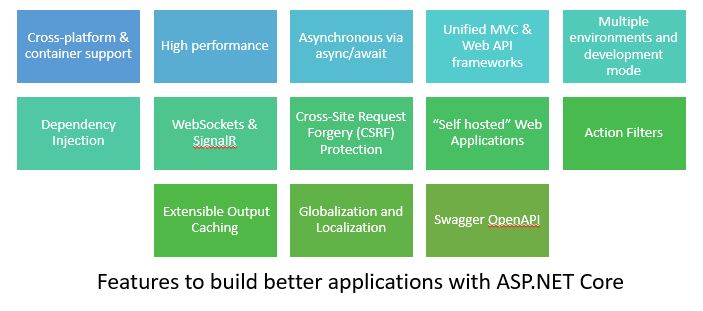
Features of ASP.net CORE 2.2
The main theme for ASP.NET Core release was to improve developer productivity and platform functionality with regards to building Web/HTTP APIs. Some of the important features of ASP.net CORE 2.2 include:
- ASP.NET Core Web Project template now updated to Bootstrap 4 that gives a fresh look to the page. Most of extra elements are removed. Default UI also supports Bootstrap 4.
- For SPA based templates now support Angular 6
- Web API improvements is the big theme for this release.
- HTTP/2 support is added.
- IIS in-process hosting model is added for IIS.
- Health checks framework is integrated now to monitor health of APIs and apps.
- Endpoint routing is introduced and takes care of several routing problems.
- ASP.NET Core SignalR Java client is added.
- Better integration with popular Open API (Swagger) libraries including design-time checks with code analyzers – ASP.NET Core 2.1 introduced the ApiController attribute to denote a web API controller class which performs automatic model validation and automatically responds with a 400 error. In 2.2, the attribute is expanded to provide metadata for API Explorer and provide a better end-to-end API documentation experience for Swagger/OpenAPI definition.
- Basically, it makes it possible for all MVC Core applications to have a good Swagger/OpenAPI definition by default. To achieve this, a set of analyzers are introduced to find cases where code doesn’t match the conventions.
- Introduction of Endpoint Routing with up to 20% improved routing performance in MVC. In 2.2, a new routing system, called Dispatcher is introduced. This is designed to run the URL matching step very early in the pipeline so that the middleware can see the Endpoint that was selected as well as metadata that is associated with that endpoint.
- Improved URL generation with the LinkGenerator class & support for route Parameter Transformers
- New Health Checks API for application health monitoring
- Up to 400% improved throughput on IIS due to in-process hosting support
- Up to 15% improved MVC model validation performance
- Problem Details (RFC 7807) support in MVC for detailed API error results
- With ASP.NET Core 2.2, Microsoft offers an OpenID Connect based authorization server, which will allow your ASP.NET application to act as an authentication point for your projects, be they web site to the API, SPA to API, native application to an API or, for distributed applications API to API.
- Preview of HTTP/2 server support in ASP.NET Core
- Template updates for Bootstrap 4 and Angular 6
- Java client for ASP.NET Core SignalR
- Up to 60% improved HTTP Client performance on Linux and 20% on Windows
- A new code generator tool to produce client side code (C# & TypeScript) for calling and using the WEB APIs.
- HTTP/2 support in Kestrel & HttpClient.
- Inbuilt plan for health check.
- SignalR to support for Java or C++.
- With ASP.NET Core 2.2, you should be able to run ASP.NET Core applications in-process in IIS, giving a significant performance boost.
Common features in ASP.NET Core 2.2 WebApi: Mapping
The data mapping is a very likely need to transform objects into other objects (similar or not) as the application layers interact with each other (dto -> domain objects and vice versa).
There are different ways to proceed. It is possible to create services, create classic static classes or extension methods.
AutoMapper is convention-based object-object mapper.
AutoMapper uses a fluent configuration API to define an object-object mapping strategy. AutoMapper uses a convention-based matching algorithm to match up source to destination values. AutoMapper is geared towards model projection scenarios to flatten complex object models to DTOs and other simple objects, whose design is better suited for serialization, communication, messaging, or simply an anti-corruption layer between the domain and application layer.
The important thing is to inherit from Profile class. When the application starts, every classes that inherit
from a Profile class will be registered by AutoMapper and the mapping strategy will be enabled.
Common features in ASP.NET Core 2.2 WebApi: Cachin
Response caching reduces the number of requests a client or proxy makes to a web server. Response caching also reduces the amount of work the web server performs to generate a response. Response caching is controlled by headers that specify how you want client, proxy, and middleware to cache responses.
The ResponseCache attribute participates in setting response caching headers, which clients may honor when caching responses. Response Caching Middleware can be used to cache responses on the server. The middleware can use ResponseCacheAttribute properties to influence server-side caching behavior.
Some cases represents a cache stored in the memory of the web server and works natively with ASP.NET Core dependency injection.
The attribute can be used to avoid any cache as well.
We can use cache with differents manners.
HTTP-based response caching
The HTTP 1.1 Caching specification describes how Internet caches should behave. The primary HTTP header used for caching is Cache-Control, which is used to specify cache directives. The directives control caching behavior as requests make their way from clients to servers and as responses make their way from servers back to clients. Requests and responses move through proxy servers, and proxy servers must also conform to the HTTP 1.1 Caching specification.
Keep in mind caching can significantly improve the performance and scalability of an ASP.NET Core app.
Common features in ASP.NET Core 2.2 WebApi: Profiling
It is quite natural to wonder about the performance of a newly developed Web API.
There are for example tools like Application Insights in Visual Studio and Azure which allow to monitor your applications, there is another Stackify Prefix tool which is free, and which allows to trace Http requests.
There are for example tools like Application Insights in Visual Studio and Azure which allow to monitor your applications, there is another Stackify Prefix tool which is free, and which allows to trace Http requests.
http://www.anarsolutions.com/features-asp-net-core-2-2/?utm-source=blogger.com